Claude Fable 5 vs Opus 4.8 — The Real Difference Nobody Is Explaining Clearly
Most people asking this question aren't confused about the specs. They're confused about whether the upgrade is worth it for them specifically.
Here's the situation: Claude Fable 5 launched on June 9, 2026. It's Anthropic's most powerful publicly available model ever. Claude Opus 4.8 launched twelve days earlier, on May 28. It's still genuinely excellent. Both are frontier models. Both cost real money. And Anthropic's own system routes Fable 5 requests back to Opus 4.8 in specific situations.
So which one should you actually be using?
That depends entirely on what you do. This comparison cuts through the benchmark noise and gives you a clean decision framework — whether you're a developer, a freelancer, a student, or someone who just wants to use the best AI tool without overpaying.
What Makes Claude Fable 5 vs Opus 4.8 an Unusual Comparison
Before the benchmarks, there's something worth understanding about how these two models relate to each other — because it's different from any comparison you've done before.
Fable 5 and Opus 4.8 are not just two versions of the same model at different price points. They're architecturally linked in a way that's unique.
Fable 5 is Anthropic's first Mythos-class model — a tier they've never released publicly before, sitting above the entire Opus family. But here's the part that most articles gloss over: Fable 5 has built-in safety guardrails for certain domains (cybersecurity, biology, chemistry). When your request touches one of those areas, Fable 5 doesn't just refuse — it hands the query directly to Claude Opus 4.8 and answers from there instead.
That means, in those situations, you're paying Fable 5 prices and receiving Opus 4.8 output.
Anthropic says this happens in under 5% of sessions. For most users, it's invisible. But if you work in security research, bioinformatics, or chemistry, that 5% is your entire use case — and you should know that upfront.
For everyone else, these are two genuinely different-capability models, and the gap is real.
Benchmarks: How Big Is the Gap Actually?
Numbers first, then the honest context.
BenchmarkClaude Fable 5Claude Opus 4.8GapSWE-Bench Pro (coding)80.3%69.2%+11.1 ptsSWE-Bench Verified95.0%88.6%+6.4 ptsFrontierCode Diamond29.3%13.4%+15.9 ptsGDPval-AA (knowledge work)1932 Elo1890 Elo+42 ptsPrice: input/output per 1M tokens$10 / $50$5 / $252x
The headline story: on coding tasks, Fable 5 leads by 11 points on SWE-Bench Pro, and on the hardest coding benchmark (FrontierCode Diamond) it's more than double Opus 4.8's score — 29.3% vs 13.4%.
But here's the honest context most benchmark articles skip: Fable 5's lead grows with task complexity. On short, well-defined tasks — summarize this, write that email, explain this concept — both models are excellent and you'd struggle to reliably tell them apart. The gap shows up on the long stuff. Multi-step pipelines. Codebase migrations. Extended research tasks. Anything where the model has to hold a lot of context and make a series of interdependent decisions.
Anthropic put it plainly in their launch notes: "The longer and more complex the task, the larger Fable 5's lead."
That framing is the most useful thing they said. Keep it in mind when you're deciding.
Pricing: The 2x Premium Explained Honestly
Claude Fable 5 costs exactly twice as much as Opus 4.8 on every pricing dimension.
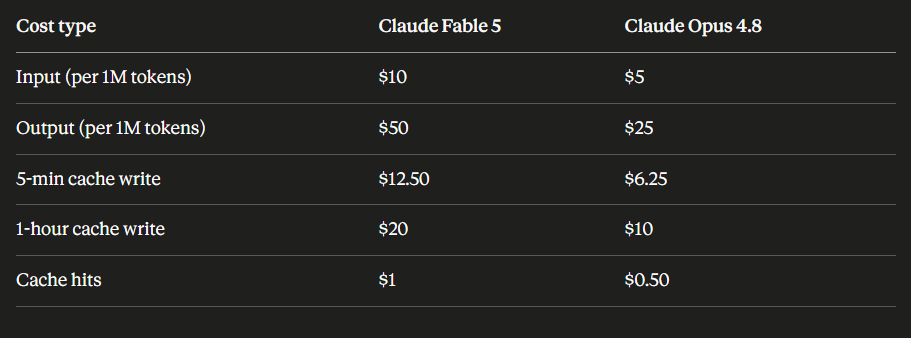
A real-world number to anchor this: a typical agentic run consuming 200,000 input tokens and 30,000 output tokens costs roughly $3.50 on Fable 5 versus $1.75 on Opus 4.8. Run that 3,000 times a month and you're looking at a $5,250 vs $2,625 monthly difference — a budget line item, not a rounding error.
But there are two cost nuances that change the math.
Nuance 1: Fable 5 is more token-efficient. Multiple customers in early testing reported Fable 5 completing complex tasks in fewer turns and fewer total tokens. A job that's 2x the per-token cost but uses 40% fewer tokens nets out to a much smaller real-world premium. On the right tasks, the actual cost difference is closer to 1.2-1.4x, not 2x.
Nuance 2: You don't pay Fable 5 rates for fallback responses. When a query gets routed to Opus 4.8 because of the safeguard classifiers, you're billed at Opus 4.8 rates, not Fable 5 rates. Small detail, but it's fair pricing.
For Indian developers and freelancers building API-based products: at current USD-INR rates (~84₹/$1), the pricing difference compounds quickly at scale. For high-volume pipelines — summarization, classification, customer support routing — Opus 4.8 at $5/$25 input/output is the economically rational choice. Reserve Fable 5 spend for the tasks that actually justify it.
Real-World Results: What Customers Actually Reported
Benchmarks are useful. What paying customers found is more useful.
Stripe used Fable 5 on a 50-million-line Ruby codebase. The model completed a full codebase-wide migration in a single day — a job their team had estimated at over two months of manual work. That's not an incremental improvement. That's a category shift in what AI-assisted engineering looks like.
A finance company (unnamed in Anthropic's launch notes) said Fable 5 was the first model to break 90% on their core analytics benchmark — a 10-point jump over Opus 4.8 on the same tests.
A spreadsheet-automation customer found Fable 5 beats Opus 4.8 at every effort level on their benchmark suite, while finishing 25-30% faster.
Replit reported Fable 5 as the top performer on their end-to-end "vibe-coding" benchmark, which tests whether a model can build real, working software from a natural-language description.
What's the pattern across all of these? Every single case involves a task that was long, complex, and had interdependent steps. None of them were "write me a quick Python function." They were all jobs where a human would need multiple hours or days.
That's the real signal. Not the benchmark table.

Five Real Scenarios — Which Model Wins Each?
Let's make this concrete with actual use cases, not hypotheticals.
Scenario 1: You're a freelance developer migrating a client's legacy codebase. → Fable 5. Clearly. Multi-file context, interdependent changes, needs to hold the whole system in mind across dozens of steps. This is exactly what Fable 5's lead was built for. The benchmark gap on FrontierCode Diamond (29.3% vs 13.4%) reflects precisely this kind of work.
Scenario 2: You're using an AI email writer or resume builder for daily professional tasks. → Opus 4.8, or even Sonnet 4.6. These tasks are well-scoped, short, and the output quality between models is indistinguishable to most users. Paying 2x for Fable 5 here is overspending. Tools like inclaw.me's AI Resume Builder or AI Email Writer are optimized for this kind of work — fast, high quality, no premium needed.
Scenario 3: You're a student writing a research paper, summarizing academic papers, or doing analysis. → Opus 4.8. Strong reasoning, excellent writing, half the price. For most academic tasks under 10,000 words, the models are functionally equivalent. Use Fable 5 if your research involves extremely long documents (500+ pages) where context degradation becomes a real issue.
Scenario 4: You're building an agentic product — a multi-step AI workflow that runs autonomously for hours. → Fable 5. This is its exact use case. Memory persistence across long tasks, recovering from failures, chaining tool calls correctly over extended runs. Anthropic's own testing showed Fable 5 improved three times more than Opus 4.8 when given access to persistent memory in long tasks. That gap compounds in agentic workflows.
Scenario 5: You need to process hundreds of documents daily for a content or legal pipeline. → Opus 4.8. High volume, well-scoped tasks, cost sensitivity. Opus 4.8 at $5/$25 gives you strong output at scale without the Fable 5 premium eating your margin. For tools like inclaw.me's AI Text Summarizer, Opus-level intelligence is more than capable for document processing work.
The India Angle: Does the Pricing Math Make Sense?
Most comparison articles are written for US developers or enterprise teams where $50/million output tokens is a line item on a much larger cloud bill. For Indian developers, indie hackers, and solo founders, the math looks different.
Here's a practical way to think about it. If you're building a product and running roughly 500 "hard" AI tasks per day (complex coding, multi-step analysis), you're looking at:
Fable 5: roughly ₹14,000–18,000/month depending on task length
Opus 4.8: roughly ₹7,000–9,000/month
For most early-stage Indian products, that delta matters. The smart approach is exactly what enterprise teams do: run Opus 4.8 as your default, route only your hardest tasks to Fable 5. You get Fable 5's capability where it matters and Opus 4.8 economics everywhere else.
On claude.ai's consumer plans, you don't pay per token — you're on a subscription. In that context, use Fable 5 whenever you have a genuinely complex task and switch to Sonnet 4.6 for quick, daily work. Opus 4.8 sits in the middle — useful for moderately complex tasks when Fable 5 would be overkill.
The Three-Model Picture: Where Does Sonnet 4.6 Fit?
Most articles only compare Fable 5 and Opus 4.8, but ignoring Sonnet 4.6 makes the decision harder than it needs to be.
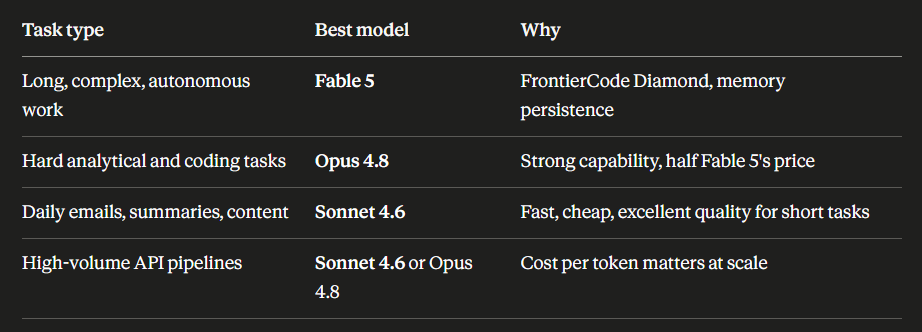
The practical rule that experienced Claude users apply: use Sonnet 4.6 for 70-80% of your work, Opus 4.8 for the harder 15-20%, Fable 5 for the 5% that's genuinely complex and high-stakes. That ratio keeps your costs rational while still accessing Fable 5's capability when it actually makes a difference.
One Thing Most Comparisons Miss: Fable 5 Has Lower Hallucination Rates
Benchmarks measure what models can do on defined tests. Hallucination rate measures something different — how often a model confidently tells you something that isn't true.
Across independent testing, Fable 5 produces fewer confident incorrect answers than Opus 4.8, especially on tasks involving long documents, complex reasoning chains, and knowledge retrieval. For anyone doing work where you can't afford to fact-check everything — legal research, financial analysis, medical summaries — that difference is worth more than any benchmark score.
Opus 4.8 is not a high-hallucination model. This isn't a significant weakness. But the gap is real, and it matters specifically in contexts where error cost is high. If your work involves dense factual content — government forms, legal documents, policy analysis — the improved accuracy from Fable 5 can save meaningful review time downstream.
Should You Actually Upgrade to Fable 5?
The honest answer is: probably not by default.
Opus 4.8 is an excellent model. It launched only 12 days before Fable 5. For most daily tasks — writing, research, summaries, coding assistance, Q&A — it delivers strong output at half the price.
Upgrade to Fable 5 when:
Your tasks regularly run longer than 30 minutes of equivalent human work
You're doing large-scale codebase work, multi-step research, or complex data analysis
Quality is the bottleneck, not cost
You're building agentic workflows that need to run autonomously without human correction mid-task
Stay on Opus 4.8 when:
Your tasks are well-scoped and under an hour in complexity
You're running high-volume pipelines where cost compounds
You need predictable latency for real-time applications
Your domain involves cybersecurity or biology (where Fable 5 falls back to Opus anyway)
The cleanest approach for most people: don't choose. Use whatever your Claude plan gives you access to, and let the task complexity guide which model you reach for. If something feels like it needs more intelligence — longer context, harder reasoning, more autonomous execution — that's your signal to reach for Fable 5.

FAQ
Is Claude Fable 5 worth it over Opus 4.8?
It depends on your tasks. For long, complex, autonomous work — large codebase migrations, multi-step research, extended agentic runs — Fable 5's lead is real and the premium pays back in saved time. For everyday tasks like emails, summaries, and short coding questions, Opus 4.8 is more than capable at half the price. The short rule: if a task would take a skilled human more than 30 minutes, Fable 5 is worth considering.
Why does Claude Fable 5 sometimes respond like Opus 4.8?
This is by design. Fable 5 has built-in safety classifiers for specific domains — cybersecurity, biology, chemistry, and model distillation. When your query touches one of these areas, Fable 5 routes it to Opus 4.8 and responds from there. Anthropic says this happens in under 5% of sessions. Importantly, you're billed at Opus 4.8 rates when this happens, not Fable 5 rates.
What is the API model string for Claude Fable 5?
The API model ID is claude-fable-5. Claude Opus 4.8 uses claude-opus-4-8. Both are available on the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
How much more expensive is Fable 5 than Opus 4.8?
Exactly 2x on paper: $10/$50 per million input/output tokens for Fable 5 vs $5/$25 for Opus 4.8. In practice, the real-world premium is often closer to 1.2-1.5x because Fable 5 frequently completes complex tasks in fewer turns and tokens than Opus 4.8 requires for the same work.
Which Claude model is best for coding in 2026?
For large-scale, production-grade coding — multi-file migrations, complex refactors, long agentic coding runs — Fable 5 is currently the strongest option available. It scores 80.3% on SWE-Bench Pro vs Opus 4.8's 69.2%, and more than doubles Opus on FrontierCode Diamond. For daily coding assistance, bug fixes, and code explanations, Opus 4.8 or even Sonnet 4.6 are perfectly capable at lower cost.
Can I use both Fable 5 and Opus 4.8 in the same application?
Yes. Many teams route by task complexity — sending hard jobs to Fable 5 and defaulting everything else to Opus 4.8. On the Anthropic API, this is simply a model ID change per request. Both models share the same API surface, so you don't need separate integrations. The model string for Fable 5 is claude-fable-5 and for Opus 4.8 is claude-opus-4-8.
Is Claude Fable 5 available in India?
Yes, globally available including India — through claude.ai paid plans, the Anthropic API, Amazon Bedrock, and Google Cloud Vertex AI. Standard API pricing applies ($10/$50 per million tokens), which at current exchange rates works out to roughly ₹840/$4,200 per million input/output tokens.